
A step-by-step guide to understanding the nuances of streaming data and its challenges.
Introduction
In today’s digital age, data is continuously generated, processed, and transmitted. This constant flow of data, often referred to as “streaming data”, presents a unique set of challenges. From ensuring timely processing to handling data in real-time, organizations are constantly seeking efficient ways to manage this influx. One of the solutions to these challenges is the concept of “Dataflow Windowing”. This blog aims to shed light on the intricacies of streaming data, the challenges it poses, and how Dataflow Windowing can be a game-changer in addressing these challenges. We will also discuss concepts like watermarks, custom triggers, and accumulation to provide a comprehensive understanding.
Streaming Data Challenges
Streaming data, by its very nature, is continuous and dynamic. As such, it presents a unique set of challenges that need to be addressed to ensure efficient and accurate processing. Here are some of the primary challenges associated with processing streaming data:
Scalability: As data streams grow in volume and frequency, the systems processing this data must be able to scale accordingly. Handling larger datasets or more frequent data updates requires robust systems that can adapt to these changes without compromising performance.
Fault Tolerance: The larger the data stream, the more crucial it becomes to ensure that the system remains operational. Any unexpected downtime can result in significant data loss or delays, making fault tolerance a top priority.
Model Selection — Streaming vs. Repeated Batch: Determining the right processing model is essential. While streaming processes data in real time, repeated batch processing handles data in chunks. Each has its advantages and challenges, and the choice often depends on the specific requirements of the task at hand.
Timing and Latency: In the world of streaming data, timing is everything. Delays in data transmission, whether due to network issues or faulty sensors, can impact the accuracy and relevance of the processed data. Ensuring minimal latency and handling late data arrivals are critical aspects of streaming data processing.
These challenges emphasise the need for advanced tools and methodologies that can address the complexities of streaming data. One such tool is Dataflow, which offers solutions like windowing to tackle these challenges head-on.
Dataflow Windowing
Dataflow Windowing is one of the core strengths of Dataflow when it comes to managing streaming data. It provides a systematic approach to handle continuous data streams by dividing them into manageable chunks or “windows”.
1. Dividing the Stream into Finite Windows
In streaming scenarios, data is divided into specific time intervals or windows. For instance, you might want to analyze the average data within a given time frame. While this might sound straightforward, maintaining these windows, especially when dealing with vast amounts of data, can be challenging. However, Dataflow simplifies this process. When reading messages from platforms like Pub/Sub, each message comes with a timestamp (usually the Pub/Sub message timestamp). This timestamp is then used to categorize the data into different time windows, making aggregation and analysis more structured.
2. Watermarks and Lag Time
One of the unique features of Dataflow is its ability to compute the “watermark”, which essentially determines how far behind the processing is from real-time data generation. This is crucial because, in streaming data, there’s always a possibility of data arriving late due to various reasons. The watermark helps in understanding the lag time and deciding how to handle late data. By default, Dataflow waits until the computed watermark has elapsed before processing a window, ensuring that most of the data for that period has arrived. Late data can either be discarded or used to reprocess the window, depending on the configuration.
3. Types of Windows
Dataflow offers three primary types of windows to fit most streaming scenarios:
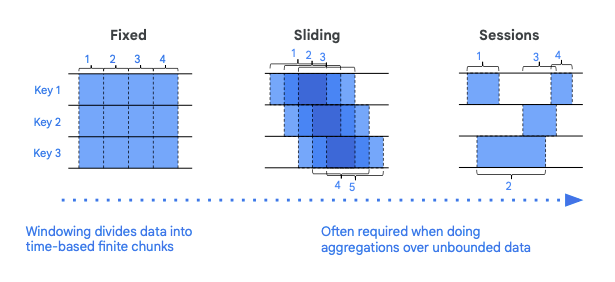
Fixed Windows: These are windows of a fixed size. For example, you might want to analyze data in 5-minute intervals.
Sliding Windows: These windows slide over the data stream, providing overlapping results. They’re useful when you want continuous insights without waiting for a fixed window to complete.
Sessions: Session windows group data based on periods of activity. They’re particularly useful for user activity tracking, where you want to analyze a user’s actions during a specific session.
Dataflow’s windowing capabilities ensure that streaming data is processed efficiently, providing timely insights while handling challenges like late data and scalability.
Watermark, Custom Triggers, and Accumulation: Simplified
Watermark
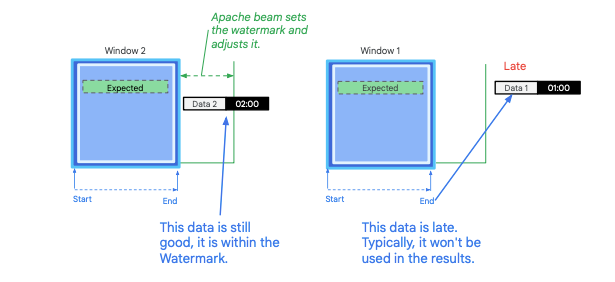
A watermark is a concept used in streaming data processing to determine how far behind real-time a data processing system might be. It provides a notion of time in the system, indicating up to what point in time the data has been processed. The watermark is used to handle the problem of data arriving late or out of order, which is common in real-time data processing systems.
Example
Imagine a system that processes data in real-time, and the data is expected to arrive at specific time intervals. Let’s say data for 01:00 arrives at 01:02, and data for 02:00 arrives at 02:03. The watermark will help the system understand that the data for 01:00 is 2 minutes late and the data for 02:00 is 3 minutes late.
Dataflow continuously computes the watermark to determine how far behind the system is. If the system has a lag of four seconds, Dataflow will wait four seconds before processing the data because that’s when it believes all the data for that time period should have arrived. If data arrives late, for example, an event with a timestamp of 8:04 arrives at 8:06 (two minutes late), you can choose how to handle this late data. The system might discard it by default, but you can also configure it to reprocess the data based on these late arrivals.
Custom Triggers
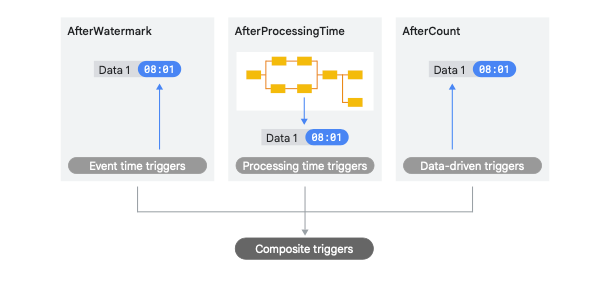
Definition: Custom triggers in streaming data processing determine when the results for a specific window of data should be processed and produced. They allow for flexibility in handling data, ensuring that results can be produced based on various conditions, such as the arrival of a certain number of data points, the passage of a specific amount of time, or even the occurrence of external events.
Example: Imagine a system that processes tweets about a trending hashtag. You might want to analyze these tweets in various scenarios:
Every time 100 new tweets arrive.
Every 5 minutes, regardless of how many tweets have arrived.
Whenever a celebrity tweets about the hashtag.
Each of these scenarios represents a different custom trigger: data-driven, time-based, and event-driven, respectively.
Dataflow allows you to set up custom triggers based on your specific requirements. The default behaviour is to trigger at the watermark, which is essentially when the system believes all data for a specific time window has arrived. However, you can also set up custom triggers, such as:
Event Time Triggers: Using the timestamps of the incoming data.
Processing Time Triggers: Based on the real-world clock time.
Data-driven Triggers: Based on the quantity of data that has arrived.
For instance, you might set a trigger to process data every 30 seconds, irrespective of the data timestamps, or another trigger to process data every time 100 new data points arrive.
Accumulation
Definition: Accumulation in streaming data processing refers to how the system handles data in a window when a trigger fires multiple times for that window. It determines whether the system should consider only the new data since the last trigger or all the data, including what was processed by previous triggers.
Example: Imagine a system that counts the number of tweets about a trending topic every hour. If a trigger is set to fire every 30 minutes:
In Discarding Mode: At the 30-minute mark, it counts tweets from the start of the hour to the 30-minute mark. At the end of the hour, it counts tweets from the 30-minute mark to the end of the hour, discarding the earlier ones.
In Accumulating Mode: At the 30-minute mark, it counts tweets from the start of the hour to the 30-minute mark. At the end of the hour, it counts all tweets from the start of the hour, including those already counted at the 30-minute mark.
Dataflow provides these two primary accumulation modes:
Discarding Mode: Each time a trigger fires, only the new data since the last firing is considered.
Accumulating Mode: Each time a trigger fires, all data in the window is considered, including data processed by previous firings.
This flexibility ensures the data processing behaviour to suit specific analytical needs, whether it’s to get incremental updates or cumulative results.
Conclusion
Google Dataflow emerges as a powerful tool, adeptly handling the intricacies of streaming data. Through its advanced features like watermarks, custom triggers, and accumulation modes, Dataflow ensures that data is processed timely, accurately, and efficiently. As we’ve explored in this guide, understanding these mechanisms is crucial for anyone looking to harness the full potential of streaming data analytics. With the challenges of data latency, out-of-order arrivals, and varying processing needs, Dataflow’s capabilities provide a robust solution.