Mastering the Basics of Reinforcement Learning: A Comprehensive Guide

In today’s fast-paced digital world, AI has become an integral part of various fields, including image classification, prediction tasks, and control tasks. Two of the most intriguing AI techniques are deep learning and reinforcement learning. However, understanding these concepts can be a bit daunting, especially when they come together in the form of deep reinforcement learning. This article aims to simplify these concepts and explain how they are transforming the realm of AI.
Deep Learning: The Power of Layers
To begin with, let’s discuss deep learning. Deep learning models are powerful parametric machine learning models used extensively for tasks such as image classification. These models have their parameters initialized to random values, which are then adjusted during training to increase their accuracy.
A primary feature of deep learning is its multi-layered structure, which enables the model to represent data in a layered manner. This is why they’re called “deep” neural networks. The process of layering allows the model to break down complex data into simpler components until they reach atomic units. The architecture mimics the compositionality of human language, with each level offering meaningful interpretations. This ability to handle complex data is a key advantage of deep learning.
The Reinforcement Learning Framework
Moving on to reinforcement learning (RL), it’s a strategy that allows models to learn from their environment, making it perfect for control tasks. In RL, we are primarily concerned with learning how to act rather than just predicting or classifying.
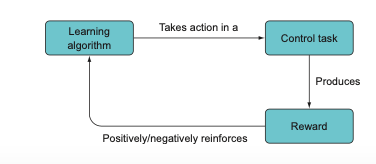
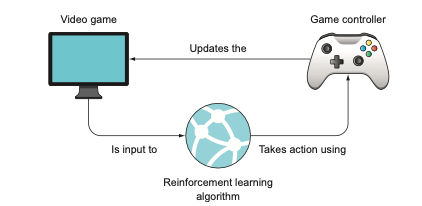
Contrary to an image classifier, a reinforcement learning algorithm engages in an ongoing, dynamic interaction with data. It consistently absorbs new data and decides on the appropriate responses — responses that subsequently modify the data it encounters next. Consider a video game: the game screen might serve as the input data for a reinforcement learning algorithm. Based on this input, the algorithm decides on a particular action to execute via the game controller, resulting in changes to the game state (for instance, the character moving or firing a weapon).
Reinforcement learning operates on a system of rewards and penalties, similar to how you might train a dog. The objective is clear: maximize the reward. This might involve learning smaller, elementary skills in the process. Positive rewards incentivize desired behaviors, while negative rewards deter undesirable actions.
However, a crucial aspect that sets RL apart is the addition of the time dimension. Unlike traditional image classification, where the data set is fixed, in control tasks, what the model decides at a given time can be influenced by past decisions, making the training task dynamic.
Dynamic Programming vs Monte Carlo
Consider this scenario: you want to train a robot vacuum to navigate from a room to its docking station in the kitchen. It has four possible actions: move left, move right, move forward, or move in reverse. The vacuum needs to decide which action to take at each moment. If it reaches the dock, it receives a reward of +100; if it bumps into something, it receives a negative reward of -10. The robot has a detailed 3D map of the house and the exact location of the dock but still doesn’t know the precise sequence of basic actions it needs to take to reach the dock.
To solve this, one method called dynamic programming (DP), first proposed by Richard Bellman in 1957, can be used. Dynamic programming essentially breaks down complex, high-level problems into smaller subproblems until reaching a simple subproblem that can be solved directly.
Rather than the vacuum devising a lengthy sequence of basic actions to reach the dock, it can first divide the problem into “stay in the room” or “exit the room”. As it has a complete map, it knows it must leave the room, as the dock is in the kitchen. But it doesn’t know the series of actions that will allow it to exit, so it further breaks down the problem into “move towards the door” or “move away from the door”. Again, it doesn’t know the sequence of basic actions to move towards the door. Finally, it decides between moving left, right, forward, or in reverse. Seeing the door in front of it, it moves forward, continuing this process until it exits the room and eventually reaches the dock.
This process encapsulates the essence of dynamic programming. It’s a universal approach to solving certain types of problems that can be divided into subproblems, and it has applications in many fields, including bioinformatics, economics, and computer science.
However, applying Bellman’s dynamic programming requires us to break our problem into subproblems that we know how to solve, and this is often difficult in real-world situations. Consider a self-driving car with the goal of “reaching point B from point A without crashing” — how can we break this down into manageable subproblems without crashing? Do children learn to walk by solving easier sub-walking problems? In RL, where we often deal with intricate situations involving some randomness, we can’t apply dynamic programming in the exact way Bellman suggested. In fact, DP and random trial-and-error can be seen as the two extremes of a spectrum of problem-solving techniques.
In some situations, we have extensive knowledge of the environment, while in others we have minimal understanding, necessitating different strategies. For instance, if you’re at your own house, you know exactly how to get to the bathroom from any starting position. But in a house you’ve never been to, you might have to search around until you find the bathroom. The latter case, trial and error, generally falls under Monte Carlo methods, essentially random sampling from the environment. In many real-world situations, we have some knowledge about the environment, and we use a mixed strategy of some trial and error and some direct solving of easy sub-objectives using our existing knowledge.
A humorous example of a mixed strategy might be if you were blindfolded and placed somewhere unknown in your house, tasked with finding the bathroom by throwing pebbles and listening for the sound. You might first break down the high-level goal (find the bathroom) into a simpler sub-goal: determine which room you’re currently in. You might throw a few pebbles in random directions and use the echo to assess the room’s size, which could help you deduce which room you’re in. Then, you might move on to another sub-goal: reaching the door to enter the hallway.
Reinforcement Learning Framework — an example
Jargon: Agent - An agent is the action-taking or decision-making learning
algorithm in any RL problem
The process of RL revolves around an agent (a learning algorithm) interacting with its environment to achieve a specific objective, with the agent’s actions based on the current state of the environment and the feedback received from prior actions.
Consider a real-life example: reducing energy usage in a large data center. Traditionally, keeping a data center cool is an expensive affair, with the air conditioning running continuously to ensure servers don’t overheat. However, this method is not energy-efficient.
Instead, you could use an RL algorithm to optimize the cooling. In this scenario, the RL algorithm or ‘agent’ is tasked with minimizing the cooling costs while ensuring the servers don’t overheat. This is the overall objective.
Next, the agent interacts with the ‘environment’ — the data center. The agent receives input data or ‘state’, which includes the current temperature of the servers and the cost of cooling. Using this state information, the agent makes a decision or ‘action’, such as adjusting the air conditioning.
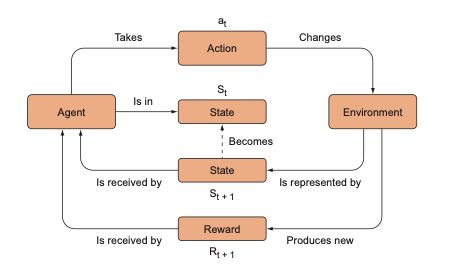
After each action, the agent receives feedback or a ‘reward’. A positive reward indicates that the action was beneficial, and a negative reward signifies an unhelpful action. For example, if the action taken by the agent reduces the energy cost, it gets a positive reward. If the energy cost increases, it gets a negative reward.
This process repeats, with the agent learning from each iteration to make better decisions. The goal of the RL algorithm is to maximize the total reward over time, learning how to navigate its environment effectively.
A more practical way to understand the RL framework is through the OpenAI Python library, which provides a wide variety of environments for learning algorithms to interact with. For example, a car racing game can be set up in just five lines of code. Here, the agent would be learning how to navigate a race car to achieve the best time.
In short, reinforcement learning is a powerful technique for solving complex problems by breaking them down into smaller parts. The agent, or learning algorithm, interacts with its environment, making decisions based on the current state and feedback from past actions. The goal of the agent is to maximize its total reward over time, ultimately learning how to effectively navigate and interact with its environment.
Impacting Industry and Beyond: The Expansive Scope of Reinforcement Learning
Reinforcement Learning (RL) is a promising area of machine learning that can be useful in developing general-purpose learning systems. These systems are capable of handling multiple problems with minimal guidance and can transfer their skills across different domains. The practicality of RL isn’t just limited to large, data-rich companies; small organizations can also reap its benefits.
In the past few years, RL has delivered impressive results. For instance, Google’s DeepMind research group designed an algorithm, the deep Q-network (DQN), which learned how to play seven Atari games with just the pixel input from the screen and a goal to maximize the score. The algorithm outperformed humans without needing any game-specific adjustments.
Another example is DeepMind’s AlphaGo and AlphaZero algorithms, which beat world champions at the ancient Chinese game Go. The complexity and vast possibilities in Go were believed to be a huge challenge for AI, but AlphaGo learned to play by simulating millions of games and figuring out which actions led to the best outcomes.
But the potential of RL isn’t confined to games. DeepMind utilized RL to reduce Google’s data center cooling costs by 40%. Autonomous vehicles are employing RL to learn the sequences of actions (accelerating, turning, braking, signaling) that safely transport passengers to their destinations.
Moreover, RL has been useful in teaching robots complex motor skills and in financial sectors such as algorithmic trading. Traders now utilize RL algorithms to adapt to real-time market conditions, which previously relied on rule-based algorithms.
Another real-world application of RL is in digital advertising, where RL algorithms are used to display the most suitable ads based on user information, maximizing the number of ad clicks and thus increasing revenue.
To sum it up, RL offers a versatile approach to learning algorithms and their applications, ranging from games and autonomous vehicles to energy efficiency and digital advertising. The strength of RL lies in its capacity to learn from interactions with its environment and improve its performance over time.
Why “Deep” Reinforcement Learning?
Reinforcement learning (RL) has been around for a while, even before the advent of deep learning. Initially, RL algorithms stored their experiences in a simple database or a lookup table. For instance, in a game of Tic-Tac-Toe, there are 255,168 valid board positions. An RL agent could maintain a table mapping each of these positions to a specific action. The RL agent would then learn the best actions by examining this table based on its gameplay experiences.
However, this lookup table approach becomes less practical as the complexity of the environment increases. Consider a video game, where every unique arrangement of pixels on the screen represents a different state. DeepMind’s DQN algorithm, which played Atari games, dealt with four 84 × 84 grayscale images at each step. This amounted to an astronomical number of unique game states, more than could feasibly be stored in any computer memory.
To overcome this challenge, we could limit the possibilities or define constraints based on our understanding of the game. However, these methods are game-specific and won’t easily generalize to other environments.
This is where deep learning comes in. Deep learning algorithms can learn to focus on the important features of a state, ignoring irrelevant pixel arrangements. Since a deep learning model has a fixed number of parameters, it can compress the vast number of possible states into a manageable representation. The Atari DQN, with its deep learning approach, only needed 1792 parameters, a significant reduction compared to the enormous number of key-value pairs required to cover all possible states.
For example, in a game like Breakout, a deep learning model could learn to recognize the position of the ball, the paddle, and the remaining blocks, just from the raw pixel data. Moreover, these learned high-level features could potentially be applied to other games or environments.
Deep learning is the key ingredient behind the recent successes in reinforcement learning. Its ability to represent complex environments efficiently and flexibly is unrivaled by other algorithms, and yet, the fundamental principles of neural networks are quite straightforward.
Summary
Reinforcement learning (RL) is a type of machine learning. RL algorithms learn to make decisions or perform actions to maximize rewards within an environment. These algorithms often use deep neural networks.
The agent is the core of any RL problem. It processes input to determine the next action. In this context, we’re mainly interested in agents implemented as deep neural networks.
The environment represents the dynamic conditions that the agent interacts with. For example, in a flight simulator, the simulator is the environment.
The state is a snapshot of the environment at a specific time, which the agent uses to make decisions. These states are samples from the continuously changing environment.
An action refers to a decision made by the agent that affects its environment. For example, moving a chess piece or pressing a car’s gas pedal are actions.
A reward is a feedback signal given to an agent by the environment after it takes an action. The aim of the RL algorithm is to maximize these rewards.
In the RL process, the agent gets input data (the environment’s state), evaluates that data, and takes an action. This action changes the environment, which then sends a reward signal and new state information to the agent. This process repeats in a loop. When the agent is a deep neural network, it evaluates a loss function based on the reward signal at each iteration and adjusts itself to improve its performance.
Reference
- Deep Reinforcement Learning in Action by Alexander Zai, Brandon Brown